Макросы dbt для ClickHouse
Бери, пригодится
Содержание

Макросы в dbt — это тема, к которой обычно приходят не из любопытства, а из боли. Если вы здесь, значит, в вашем ClickHouse-проекте уже есть три одинаковых CASE WHEN, два слегка отличающихся JOIN и навязчивое ощущение неловкости: то ли трусы надо поправить, то ли рефакторинг провести.
Что такое макросы в dbt?
Макросы - это функции, написанные на странном синтаксисе шаблонизатора jinja, и лежащие по умолчанию в папке macro. В начале папка безвидна и пуста, так что нужно сотворить их самостоятельно. В интернете полно готовых решений, я поделюсь некоторыми из тех, что мы используем на проектах.
Для чего нужны макросы в dbt?
- С помощью макросов можно переиспользовать код и избежать его дублирования
- Это позволяет также управлять бизнес логиков в одном месте, откуда она распространяется во всех нужных моделях
- Помимо типизированных выражений в макрос можно спрятать и громоздкую логику, что улучшит читаемость кода
- Если по какой-то причине вы регулярно меняете субд, то макрос поможет адаптировать SQL соответственным образом
- В макросах доступных как стандартные для jinja конструкции, так и специальные функции и переменные dbt. А это значит, что SQL можно нехило прокачать и выйти за границы дозволенного, если вы понимаете, о чём я 😉
- Для адаптеров, а так же благодаря осознанности коллеги из dbtlabs, можно переопределять поведение dbt в некоторых сценариях тоже через макросы, задавая предопределенные названия.
Схема таблиц
Dbt обычно материализует данные в базе по пути database.schema.table, однако в ClickHouse схема отсутствует. Согласно документации по этой причине адаптер использует schema.table, где schema - это database в КХ. И если указать в конфигурации модели schema='dev', то адаптер попытается создать базу database_dev, а если database='dev', то всё сработает.
Я ничего не понял, и чтобы не путаться, заменил стандартную функцию генерации имени схемы.
{% macro generate_schema_name(custom_schema_name, node) -%} {%- set default_schema = target.schema -%} {%- if custom_schema_name is none -%} {{ default_schema }} {%- else -%} {{ custom_schema_name }} {%- endif -%}{%- endmacro %}Генерация дат
{% macro generate_dates(date=None, days=5000) -%}( select {% if date is none -%} today() {%- else -%} toDate('{{ date }}') {%- endif %} - number as date from numbers({{days}})) as dates{%- endmacro %}Когда во временных рядах есть пропуски, можно сджойнить таблицу со сгенерированным датами, которая всегда под рукой
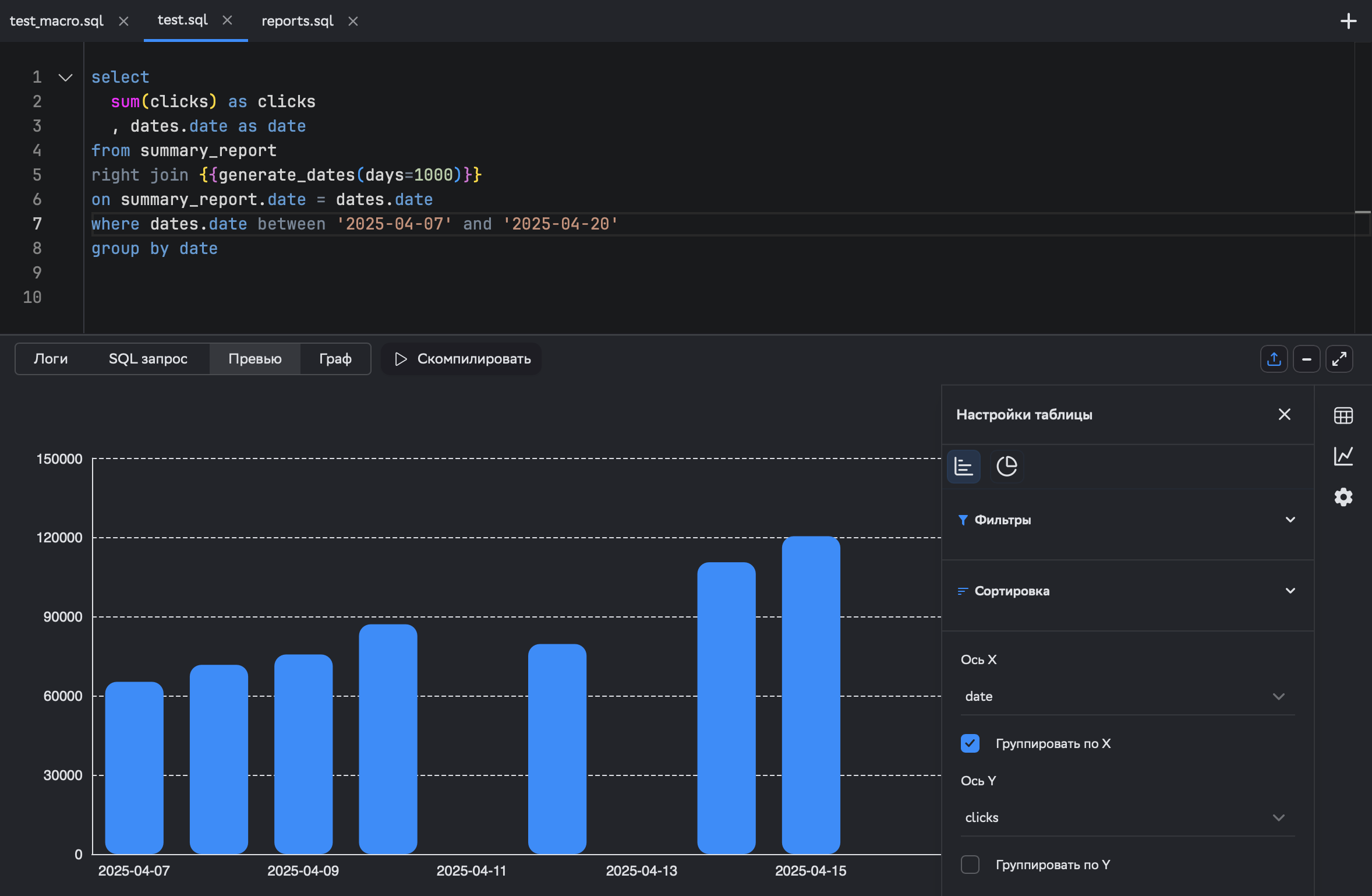
select sum(clicks) as clicks , dates.date as datefrom summary_reportright join {{generate_dates(days=1000)}}on summary_report.date = dates.datewhere dates.date between '2025-04-07' and '2025-04-20'group by dateИ в нашем новом инструменте для графиков сразу видно провалы. В смысле, не в инструменте провалы.. в данных!
Словари
{% macro format_camp(t) %}{% set t = {"creo":"_multi_", "creo_name":"мультиформат"}, {"creo":"_preroll_", "creo_name":"преролл"}, {"creo":"_post_", "creo_name":"пост "}, {"creo":"_clip_", "creo_name":"клипы"}, {"creo":"_tgb_", "creo_name":"ТГБ"}, {"creo":"_lead_", "creo_name":"лид формы"}, {"creo":"_dzen_", "creo_name":"дзен "}, {"creo":"_vid_", "creo_name":"видео"}, {"creo":"_carousel_", "creo_name":"карусель"}, {"creo":"_story_", "creo_name":"истории"}, {"creo":"_prospecting_", "creo_name":"проспектинг"}, {"creo":"_dinrem_", "creo_name":"динамический ретаргетинг"} %}{% for value in t %} WHEN match(lower(campaign), lower('{{ value.creo }}')) THEN '{{ value.creo_name }}'{% endfor %}{% endmacro %}Это наглядный пример переиспользования кода. Мы описываем атрибутирование кампании типом креатива в одном месте и потом переиспользуем везде, где нужно. Тут ещё используется цикл, чтобы поменьше писать и поудобнее править.
Инкрементальные обновления
Мы много работаем с большими объемами, делаем инкрементальные обновления и из-за специфики маркетинговых данных постоянно занимаемся дедупликацией. Следующая серия макросов про это.
Простой вариант
Есть ленивые голубцы, а есть ленивые макросы 😆 Это простое решение позволит поддерживать таблицу в актуальном состоянии, подтягивая новые данные.
{% macro incremental_filter_ch(column) %} {% if is_incremental() %} where {{ column }} > (select max({{ column }}) from {{ this }}) {% endif %}{% endmacro %}Пример использования
select * from events{{ incremental_filter_ch('event_time') }}Даты
Для частых перерасчетов удобно пользоваться макросами с датами, у нас их целая куча. Один из самых часто используемых по умолчанию возвращает вчерашний день (позволяя регулировать это) или возвращает значения по ключу передаваемой переменной.
{% macro var_or_daysago(key, n=1) -%} {% set _ndaysago = (modules.datetime.datetime.now() - modules.datetime.timedelta(days=n)).strftime('%Y-%m-%d') -%} {% set result = var(key, default=_ndaysago) -%} toDate(parseDateTimeBestEffort('{{ result }}')){%- endmacro %}В инкрементальных моделях его можно подставить в фильтр с = или between или ещё как.
where date between {{ var_or_daysago('start_date', 30) }} and {{ var_or_daysago('end_date', 1) }}Если мне надо пересчитать за выбранный период, то при запуске я указываю нужные значения в переменных.
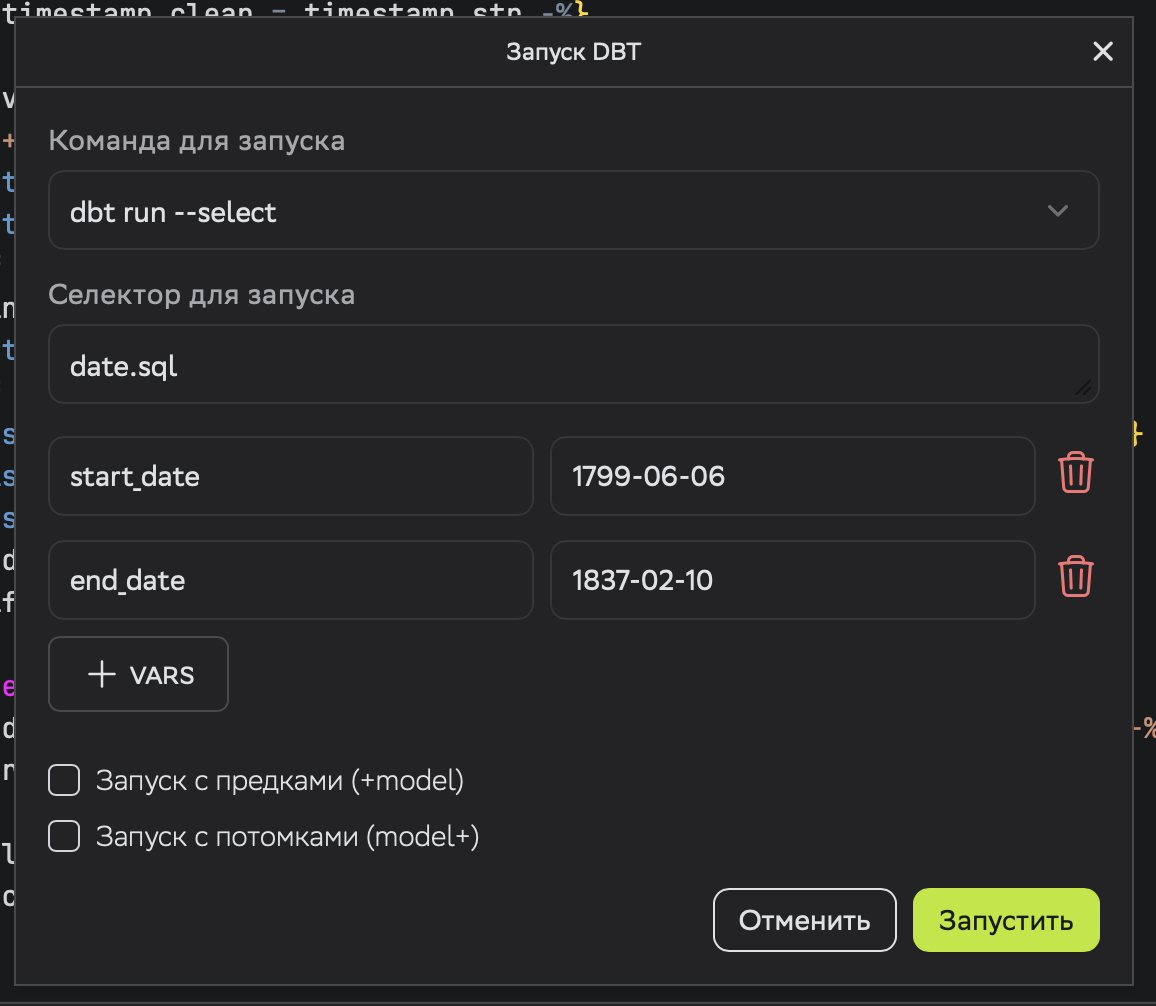
Если мне нужно дедуплицировать, предварительно удалив старые записи, то тот же макрос используется в pre_hook. Сперва проверяем, что запуск инкрементальный, иначе удаление может выдать ошибку, а потом yeahbuddylightweightbaby с параметрами. Главное - не налажать с кавычками.
{{ config( pre_hook = "{% if is_incremental() %}delеte from {{this}} on cluster {{target.cluster}} where date between {{ var_or_daysago('start_date', 30) }} and {{ var_or_daysago('end_date', 1) }} {% endif %}") }}Я не рекомендую данную стратегию дедупликации, но, когда есть выбор, это хорошо.
Партиции
ClickHouse очень не любит мутаций. Они про это целую статью написали и вообще рекомендуют производить мутации только администратору БД 😅 Одна из очевидных стратегий дедупликаций - замена партиций.
Нашёл вот такой пример генерации запроса на удаление. Его предназначение - сформировать массив названий недельных партиций за период, а потом перечислить их в дропе.
{% macro prehook_drop_partition_yyyyww(this, startDate, endDate) -%} {% set start_week_date = modules.datetime.datetime.strptime(startDate, '%Y-%m-%d') - modules.datetime.timedelta(days=modules.datetime.datetime.strptime(startDate, '%Y-%m-%d').weekday()) %} {% set end_week_date = modules.datetime.datetime.strptime(endDate, '%Y-%m-%d') - modules.datetime.timedelta(days=modules.datetime.datetime.strptime(endDate, '%Y-%m-%d').weekday()) %} {% set diff_weeks = ((end_week_date - start_week_date).days // 7) + 1 %} {% set week_list = [] %} {% for i in range(diff_weeks) %} {% set week_date = start_week_date + modules.datetime.timedelta(weeks=i) %} {% set week_str = week_date.strftime('%G%V') %} {% do week_list.append(week_str) %} {% endfor %} alter table {{ this }} on cluster {{target.cluster}} {% for week in week_list %} drop partition {{ week }} {%- if not loop.last %},{% endif %} {%- endfor %}{%- endmacro %}Пример использования
pre_hook ="{{ prehook_drop_partition_yyyyww(this, var_or_daysago_raw('start_date', 65), var_or_daysago_raw('end_date', 1)) }}"Проверка дублей в источнике
{% macro check_unique_key(source_ref, columns) %} {% set columns_str = columns | join(', ') %} with duplicates AS ( select count(*) AS count from {{ source_ref }} group by {{ columns_str }} having count(*) > 1 ) select count(*) AS duplicate_count from duplicates{% endmacro %}Пример использования в другом 🤯 макросе
{% macro validate_duplicate_in_source_table(source_ref, columns) %} {% set result = run_query(check_unique_key(source_ref, columns)) %} {% set duplicate_count = result.columns[0].values()[0] if result else 0 %} {% if execute %} {% if duplicate_count > 0 %} {{ log("Дубликаты найдены в " ~ source_ref ~ ". Таблица " ~ source_ref ~ " будет проигнорирована.", info=True) }} {{ return("(select * from " ~ source_ref ~ " where date = today() limit 1)") }} {% else %} {{ log("Дубликаты не найдены в " ~ source_ref, info=True) }} {{ return(source_ref) }} {% endif %} {% endif %}{% endmacro %}Что тут происходит? Проверяем наличие дублей по ключу. Если нашлись, выдаём предупреждением и скипаем источник болванкой. Если дублей нет - всё ок, просто логируем факт проверки и разрешаем обратиться к источнику. Соответственно, в моделях в него оборачивается ref.
from {{ validate_duplicate_in_source_table(ref('campaign_data'), ['date', 'campaign_id', 'placement_id']) }}Проверка репликации
{% macro validate_replication(model, cluster_name='default') %} {%- set query %} select fqdn(), table from clusterAllReplicas({{cluster_name}}, system.tables) where database = '{{ model.schema }}' and table = '{{ model.name }}' and total_rows = 0 {%- endset %} {%- set result = run_query(query) %} {% if execute %} {% if result|length > 0 %} {{ exceptions.raise_compiler_error("🚨 Data is NOT synchronised on all replicas in the table " ~ model) }} {% else %} {{ log("✅ Data is synchronised on all replicas in the table " ~ model, info=True) }} {{ return(model) }} {% endif %} {% endif %}{% endmacro %}По разным причинам репликации данных между нодами ClickHouse может задерживаться. В этом случае мы не хотим продолжать отношения с дагом и бросаем его. Если не хотите сами сообщать родственникам, они могут подписаться на уведомления об ошибках в запусках через планировщик. Мы пришлём письмо с причиной 😘
Распределенные таблицы
{% macro create_distributed_table(local_table, cluster_name='default') %} create table if not exists {{ this.database }}.{{ this.name }}_dist on cluster {{ cluster_name }} as {{ this.database }}.{{ local_table }} engine = Distributed( '{{ cluster_name }}', '{{ this.database }}', '{{ local_table }}', rand() ){% endmacro %}Идея простая - сделали таблицу и пост хуком распределяем её на кластер, например, для целей шеринга коллегам на том берегу. Я им не пользовался.
{{ config(post_hook=create_distributed_table(this.name, 'my_cluster')) }}TTL выражения
Для больших таблицы мы используем гибридное хранение: самые свежие данные лежат на ценном ssd, чуть старше на hdd и невостребованные в S3 холодильники. Вообще конечно тити-эли бывают всякие, но мы любим их все.
{% macro generate_ttl(column_name, ttl_days, action='delete') %} {% if action == 'to_volume' %} {{ column_name }} + interval {{ ttl_days }} day to volume 'archive' {% elif action == 'to_disk' %} {{ column_name }} + interval {{ ttl_days }} day to disk 'cold' {% if action == 'to_dick' or action == 'delete' %} {{ column_name }} + interval {{ ttl_days }} day {% endif %}{% endmacro %}Пример использования
{{ config( engine='MergeTree()', order_by='event_date', ttl=generate_ttl('event_date', 365)) }}Union all для ретроданных
Судьба нас конечно много к чему не готовила, но эксельки за доковидные года загружать и подклеивать умеем. Суть этого отрывка в том, чтобы аккуратненько взять и склеить похожие таблички.
{% macro union_tables(database, table_pattern, exclude_columns=[]) %} {% set tables_query %} select name from system.tables where database = '{{ database }}' and name like '{{ table_pattern }}' {% endset %} {% set tables = run_query(tables_query).columns[0].values() %} {% for table in tables %} select {% if exclude_columns %} * except({{ exclude_columns | join(', ') }}) {% else %} * {% endif %} from {{ database }}.{{ table }} {% if not loop.last %} union all {% endif %} {% endfor %}{% endmacro %}Пример использования
{{ union_tables('analytics', 'events_%', exclude_columns=['internal_field']) }}