Кастомные материализации dbt: из ClickHouse в S3
Укладка паркета, дёшево
Содержание

Однажды меня попросили уложить паркет 🤭
А если конкретно, то мне потребовалось на регулярной основе перекладывать данные из таблицы внутреннего закрытого ClickHouse в S3 бакет для передачи партнеру.
Эту задачу можно решить кучей способов, но у нас есть SubQuery с dbt и расписанием, так что я решил пробовать написать кастомную материализацию.
Предварительные работы
Перед тем как писать материализацию, нужно подготовить инфраструктуру:
S3 Bucket
Мы работаем с облаком Яндекса. Там проще всего завести через UI, но можно и через консоль.yc storage bucket create --name my-dbt-bucket --default-storage-class standardЗапомните endpoint (например,
https://storage.yandexcloud.net) и регион.Настройте доступ к бакету из ClickHouse. В Clickhouse для этого лучше использовать коллекции — набор credentials (ключ доступа, секрет, endpoint), который можно переиспользовать в разных моделях.
Создайте коллекцию типа
s3через интерфейс SubQuery или API, указав:- Access key ID и Secret access key (например, сервисный ключ Yandex Cloud).
- Endpoint (например,
https://storage.yandexcloud.net). - Регион (опционально).
Совет: называйте коллекции префиксом с их типом, напримерs3_илиpostgres_. Так в них потом проще ориентироваться.Убедитесь, что ClickHouse умеет работать с S3 через функцию
s3(). Обычно это требует правильной версии ClickHouse и настроенного HTTP‑транспорта.
Подробнее о подключении S3 к ClickHouse читайте в нашей статье: Работа с S3 в ClickHouse.
Jinja и макросы в dbt
dbt использует шаблонизатор Jinja2 для внедрения логики в SQL‑код. Это позволяет писать динамические запросы, повторно использовать фрагменты кода (макросы) и управлять конфигурацией на лету.
Макросы — это функции на Jinja, которые живут в папке macros/ вашего dbt‑проекта. Они могут принимать аргументы, возвращать SQL‑строки и вызываться из моделей, подобно встроенным функциям.
Например, вместо того чтобы копировать один и тот же CASE WHEN в десятке моделей, вы выносите его в макрос и вызываете отовсюду. Это не только сокращает объём кода, но и упрощает поддержку: изменение логики в одном месте автоматически применяется ко всем зависимым моделям.
Если вы раньше не работали с Jinja, достаточно запомнить три основных синтаксических элемента:
- Выражения
{{ ... }}— подставляют значение переменной или результат вызова макроса. - Управляющие конструкции
{% ... %}— циклы, условия, объявление переменных. - Комментарии
{# ... #}— не попадают в итоговый SQL.
В контексте кастомных материализаций Jinja используется для генерации DDL/DML‑операций, которые выполняются адаптером (в нашем случае — ClickHouse). Сама материализация по сути является макросом специального вида, который dbt вызывает при сборке модели.
Подробнее о макросах для ClickHouse можно прочитать в нашей отдельной статье: Макросы dbt для ClickHouse.
Кастомные материализации в dbt
Стандартные материализации dbt — table, view, incremental и ephemeral — покрывают большинство сценариев, но иногда требуется сохранить результат модели не в таблицу БД, а, например, в файл S3, отправить в очередь или записать в сторонний API. Для таких случаев dbt позволяет писать кастомные материализации.
Кастомная материализация — это макрос, который определяет, как dbt должен выполнить модель. Он должен:
- Принимать конфигурацию модели (через
config.get()). - Генерировать нужный DDL/DML‑код (обычно с помощью
{% call statement() %}). - Вызывать хуки (
run_hooks(pre_hooks)иrun_hooks(post_hooks)), если они заданы. - Возвращать словарь с relations (или пустой список, если отношения не создаются).
Материализация объявляется вот так
{% materialization имя, adapter='адаптер' %}...{% endmaterialization %}Внутри можно использовать любые Jinja‑конструкции, а также обращаться к объектам dbt:
this— текущая модель (её имя, схема, база данных).sql— SQL‑код модели (то, что написано вselect ...).config— конфигурация модели (аргументы из{{ config(...) }}).run_hooks()— выполнение pre‑ и post‑хуков.statement()— выполнение SQL‑запроса через адаптер.
Обязательные блоки внутри материализации:
- Объявление переменных
{% set overwrite = config.get('overwrite', False) %}- Вызов pre‑хуков
{{ run_hooks(pre_hooks) }}- Основной SQL‑запрос
{% call statement('main') %...{% endcall %}- Вызов post‑хуков
{{ run_hooks(post_hooks) }}- Возврат результата
{{ return({'relations': []}) }}Если материализация создаёт таблицу (или другое отношение), его нужно добавить в возвращаемый список, чтобы dbt мог управлять его жизненным циклом. В нашем случае мы не создаём таблицу в БД, поэтому вернём пустой список.
Кастомные материализации размещаются в папке macros/ и автоматически подхватываются dbt при запуске. Имя материализации (первый аргумент materialization) используется в {{ config(materialized='имя') }}.
Написание материализации
{% materialization s3_parquet, adapter='clickhouse' %} {%- set overwrite = config.get('overwrite', False) -%} {%- set account = this.identifier -%} {%- set datetime_column = config.get('datetime_column', 'date') -%} {%- set file_path = 'source=subquery/account=' ~ account ~ '/{_partition_id}/data.parquet.gz' -%} {%- set partition_expr -%} formatDateTime({{ datetime_column }}, 'year=%Y/month=%m/day=%d') {%- endset -%} {{ run_hooks(pre_hooks) }} {%- call statement('main') -%} insert into function s3( s3_collection, filename='{{ file_path }}' ) partition by {{ partition_expr }} {{ sql }} {% if overwrite -%} settings s3_truncate_on_insert=1 {%- endif -%} {%- endcall %} {{ run_hooks(post_hooks) }} {{ return({'relations': []}) }}{% endmaterialization %}Как это выглядит в S3
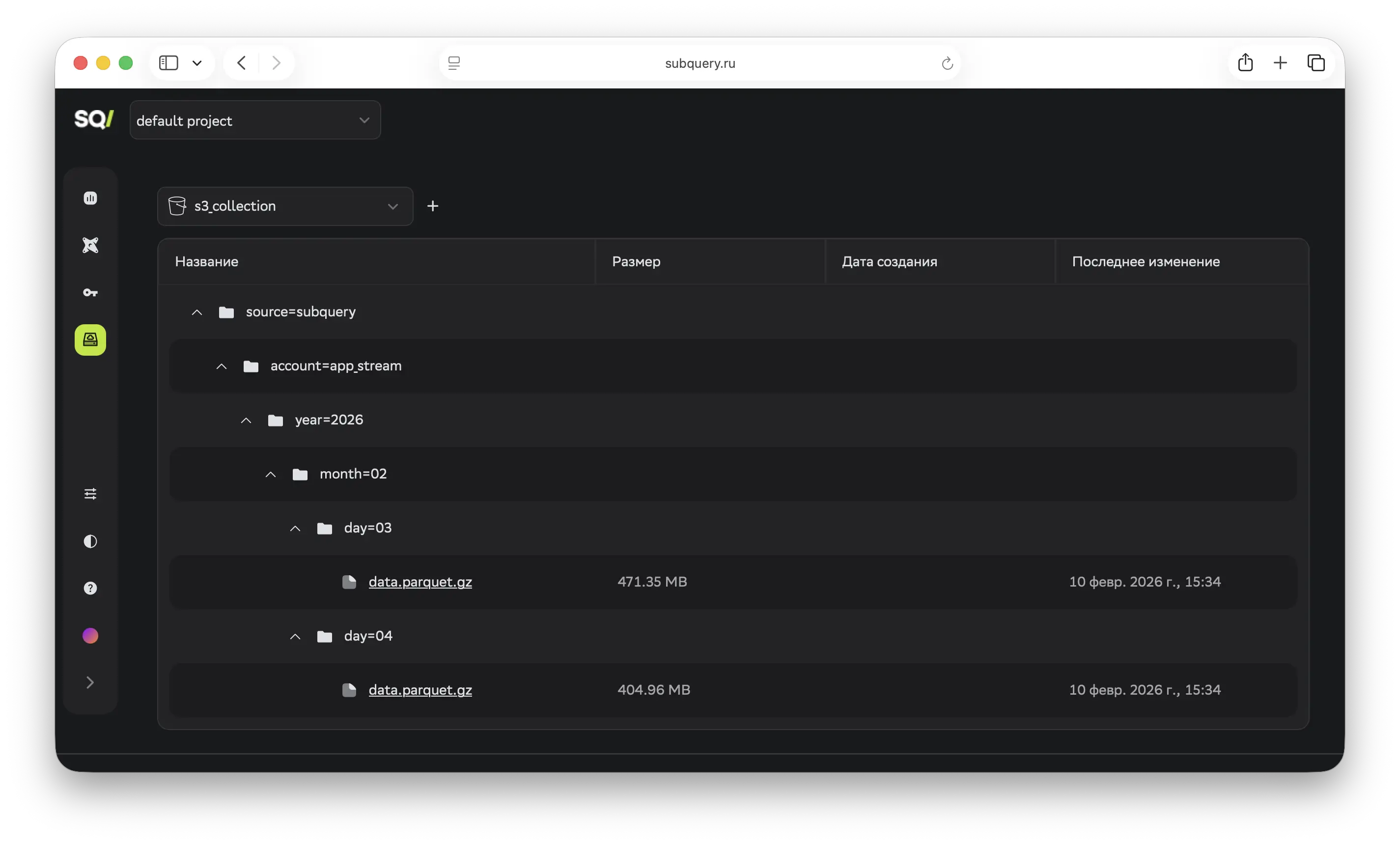
После выполнения материализации данные оказываются в S3 в виде сжатых Parquet‑файлов, разложенных по папкам согласно партицированию.
Структура пути формируется по шаблону:
source=subquery/account=<account>/year=2025/month=01/day=15/data.parquet.gzГде:
source=subquery— фиксированный префикс (можно менять в материализации).account=<account>— идентификатор модели (берётся изthis.identifier).year=.../month=.../day=...— партиции по дате, которые автоматически генерируются из колонкиdatetime_column.
Каждый файл содержит данные за один день (если партицирование дневное) и сжат gzip. Формат Parquet обеспечивает эффективное хранение и возможность прямого запроса через инструменты Trino, DuckDB или того же ClickHouse.
В SubQuery можно подключить свой бакет и просматривать файлы через веб‑интерфейс — это удобно для быстрой проверки, что данные выгрузились корректно.
Пример использования в моделях
Вот как выглядит модель, которая использует нашу кастомную материализацию:
{{ config( materialized='s3_parquet', overwrite=True, alias='app_stream', datetime_column='toDateTime(timestampcolumn)') }} select *from {{ source('raw_data', 'view_app_stream') }}where toDate( {{ config.get('datetime_column') }} ) between {{ var_or_daysago('start_date', 3) }} and {{ var_or_daysago('end_date', 1) }}Разберём параметры конфигурации:
materialized='s3_parquet'— указывает dbt использовать нашу кастомную материализацию.overwrite— если в S3 уже есть файлы за те же партиции, они будут перезаписаны (включается настройкаs3_truncate_on_insert=1). Это полезно при обновлении данных в источнике.alias— имя модели, которое станет частью пути в S3 (account=app_stream).datetime_column— колонка, по которой будет производиться партицирование. Можно передать любое выражение, возвращающее DateTime.
В условии WHERE используется макрос var_or_daysago. Он работает так:
- Если в переменных dbt (
{{ var('start_date') }}) задано конкретное значение, макрос подставит его. - Если переменная не определена, макрос вернёт дату, отстоящую на N дней назад от текущей (в примере — 3 дня для
start_dateи 1 день дляend_date).
Это позволяет гибко управлять периодом выгрузки: в обычном режиме модель каждый день выгружает «вчерашние» данные, но при необходимости можно явно указать start_date и end_date через dbt run --vars и пересчитать любой исторический интервал.
Макрос var_or_daysago — один из многих полезных макросов, которые мы собрали в статье Макросы dbt для ClickHouse.
Добавление в расписание
Готовую модель можно запускать по расписанию, чтобы данные в S3 всегда были актуальными. В модуле dbt SubQuery, находясь в основной ветке, выберите справа вверху «Расписание», создайте новое, укажите селектор модели (или весь проект) и задайте cron‑выражение, например 0 2 * * * (каждый день в 02:00).
Можно заказать алерты на почту, тогда мы напишем, если выполнение модели завершится неуспешно.
Благодаря макросу var_or_daysago модель автоматически выбирает период выгрузки: каждый день она будет выгружать данные за предыдущий день (или за другой интервал, который вы настроили). Если нужно пересчитать историю, можно временно переопределить переменные start_date и end_date через dbt run --vars.
Такое расписание гарантирует, что в S3 всегда будут свежие Parquet‑файлы, готовые для аналитики в других системах.
Полезные ссылки
- Официальная документация dbt по кастомным материализациям
- Jinja для dbt: синтаксис и примеры
- ClickHouse адаптер для dbt
- Статья «Макросы dbt для ClickHouse»
- Работа с S3 в ClickHouse
Если у вас остались вопросы или нужна помощь с настройкой — пишите в Telegram‑канал SubQuery